使用深度学习检测XSS(续)
一、前言
最近腾出时间重新搞一下这个算法,对数据集、模型参数做了简单的优化,对不同算法在GPU/CPU上的性能进行了对比,并部署在生产环境实际测试。另外,@cdxy使用SVM进行分类获得了更高的性能,但具有很低的泛化能力,本文把这个算法放到这里一并讨论,原文链接:https://www.cdxy.me/?p=773。
二、数据集优化
我这里有两套生产环境的数据,每套环境的系统不同,http流量一大一小,训练数据取自流量大的环境,训练数据选取更小时间段的流量,只有6天。部署到生产环境时,检测数据源包括两个环境。减少训练数据量和只取一个环境的数据,目的是考察模型在真实环境的泛化能力。
原训练数据的白样本只取了GET请求,这次加入POST请求,白样本由20万条减少到7.3万,黑样本保持不变。
三、模型参数优化
为了减小模型占用的资源,对参数作如下优化:
- 词向量的维度由128减小到32
- 单条数据的分词数量由maxlen变成固定的200,意味着分词数量超过200将被截断。
- 神经网络的batch大小由200减小为50
- 各模型的神经元数量适当减小
四、性能对比
SVM使用sklearn的线性SVM,各模型的准确度和召回率均在99%左右,性能SVM最优,LSTM
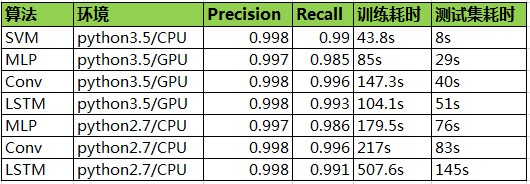
五、生产环境表现对比
模型检测从9月1号到10月8号生产环境中的数据,告警的数量如下表,SVM产生了大量的误报,运行少量数据就停掉了,所以表中未统计。
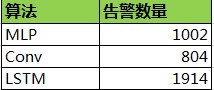
- 在测试数据集上表现不错的SVM为什么泛化能力会很差?
先回顾一下算法构建词表和样本向量的过程:用正则对黑样本分词,取词数量的top N作为词表,不在词表中的词取“UNK”。将一个样本的分词padding到200,不足200的取全0,最终每一条数据都变成一个1×200×32的多维矩阵,在SVM中需要将此矩阵展平为1×6400维的向量,展平相当于词向量拼接到一起构成样本向量。
SVM认为特征之间是相互独立的,因此是无法识别词位置和词与词之间的关系,比如“< script“在第2个词或第5个词对分类结果的影响应该是相同的,但是svm在不同的位置却表示了不同的特征。构建词表的方法意味着,测试数据中的黑样本的分词结果包含更多非”UNK”的词,白样本分词结果包含更少的非“UNK”的词,因此在测试数据中黑白样本在空间中是可分的。但是生产环境是非常复杂多样的,当遇到包含较多非“UNK”词的正常数据时,SVM是缺乏足够的学习能力的。
- 深度学习的误报分析
三个算法产生的告警经人工分析,均没有XSS(难道传统企业真的不受web白帽们的待见???)。产生的误报可分为两类:
将正常数据识别为xss,如包含referer参数或url、登录行为、post数据为html或javasript等。




另一类误报非常有意思,神经网络将其他类的攻击识别为xss,如sql注入、各种n-day(strust2、phpcms)、webshell等。




六、靶机测试
检测了一个多月的实际数据未检测出xss,搭建个靶机模拟下攻击流量,考察下检出能力。靶机选择DVWA,包括一个反射型和一个存储型漏洞。除了各难度等级的利用姿势外,从网上挑选一些复杂的xss payload,测试结果见下表,绿色代表检测出,红色代表未检测出。
反射型:

存储型:

七、总结与思考
- 深度学习相对传统机器学习具有更好的泛化能力,能够学习到更高维度的特征。
- LSTM检出能力更强,但是以牺牲准确率为代价。
- 由于模型是个二分类模型,面对其他类型的异常数据时,模型认为他们更加接近于xss。为了降低此类误报可以加入其它类攻击数据,训练一个多分类模型,或者训练一个“正常-异常”的二分类模型
- 深度学习模型的参数更多,因此需要更多的训练数据,本文用到的数据量对于深度学习是不够的。
- 增加白样本数据量应可以减少误报,但会面临两个问题:如何从真实数据中清洗出白样本,人工标注是不现实的;单纯增加白样本会导致数据不均衡,如何解决?
The article is not allowed to repost unless author authorized

Welcome to follow my wechat



